I am a senior research scientist at NVIDIA. I obtained my Ph.D. in Computer Science at the University of Rochester, under the supervision of Prof. Jiebo Luo.
My recent research focus is visual generative modeling, including research on foundational generative models like pixel-space diffusion models, generative rendering, text-to-game generation, streaming video generation, interactive world models, etc. I am also interested in image composition, relighting, shadow synthesis, and representation learning.
I am looking for research interns to explore streaming video generation, pixel diffusion, etc. Meanwhile, I am open to long-term university research collaborations,
where I can provide mentorship for research projects, including: high-level and detailed research ideas, co-debugging if necessary.
If you are interested, feel free to reach out with your resume.
Jun. 2022 -- I obtain my Ph.D from the University of Rochester. See my PhD thesis. Many thanks to my advisor Jiebo Luo, my mentors and collaborators, who have giving me this unforgettable experience.
I am recently focusing on visual generative modeling, especially content creation with identity preservation, including generative image enhancement and and personalized visual concept generation.
Representative works are highlighted. See full list in my Google Scholar.
PixelDiT scales diffusion transformers directly in pixel space, pretraining at 1024×1024 resolution to deliver high-fidelity text-to-image generation and editing.
We propose DINO-guided Video Editing (DIVE), a framework designed to facilitate subject-driven editing in source videos conditioned on either target text prompts or reference images with specific identities.
We propose Multi-Modal Image Generation Benchmark (MMIG-Bench), a comprehensive benchmark for evaluating multi-modal image generation models. MMIG-Bench unifies compositional evaluation across T2I and customized generation, introduces explainable aspect-level metrics, and provides extensive human and automatic evaluations.
We propose a new approach to improve the identity preservation of generated objects. Specifically, we automatically locate and align the visual tokens in the reference with the target region that needs to be refined.
We introduce GroundingBooth, a framework that achieves zero-shot instance-level spatial grounding on both foreground subjects and background objects in the text-to-image customization task.
We introduce SwapAnything, a novel framework that can swap any objects in an image with personalized concepts given by the reference, while keeping the context unchanged.
Our work achieves advanced image composition with a decent identity preservation, automatic object viewpoint/pose adjustment, color and lighting harmonization, and shadow synthesis. All these effects are achieved in a single framework!
We introduce Relightful Harmonization, a lighting-aware diffusion model designed to seamlessly harmonize sophisticated lighting effect for the foreground portrait using any background image.
We propose InstantBooth, a novel approach built upon pre-trained text-to-image models that enables fast personalized text-to-image generation without test-time finetuning.
My PhD thesis summarizes my main research works on Guided Visual Content Creation during my PhD program. Part I introduces guidance-driven visually pleasing data synthesis. Part II presents guidance-driven synthesis for downstream visual recognition tasks.
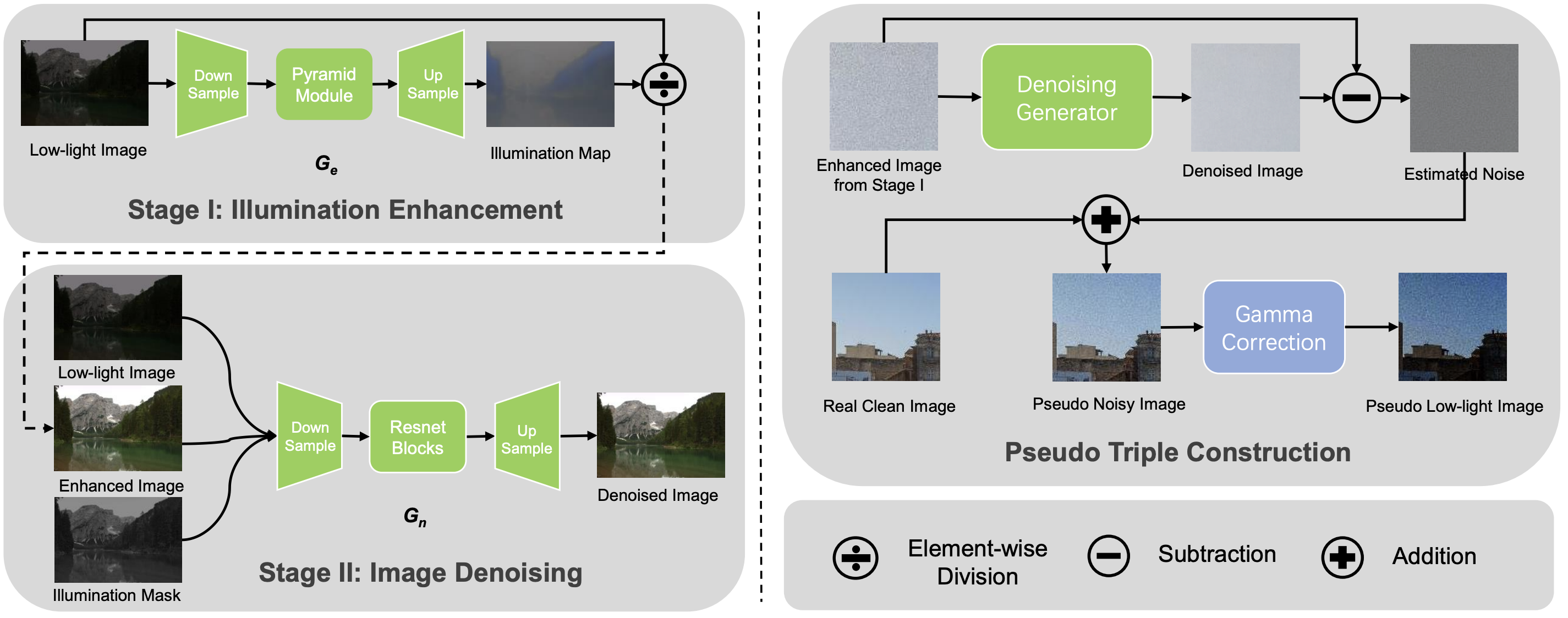
We are among the few pioneering works on unsupervised real-world low-light image enhancement. Specifically, we tackle the problem of enhancing
real-world low-light images with significant noise in an unsupervised fashion. To this end, we explicitly
decouple this task into two sub-problems: illumination enhancement
and noise suppression.
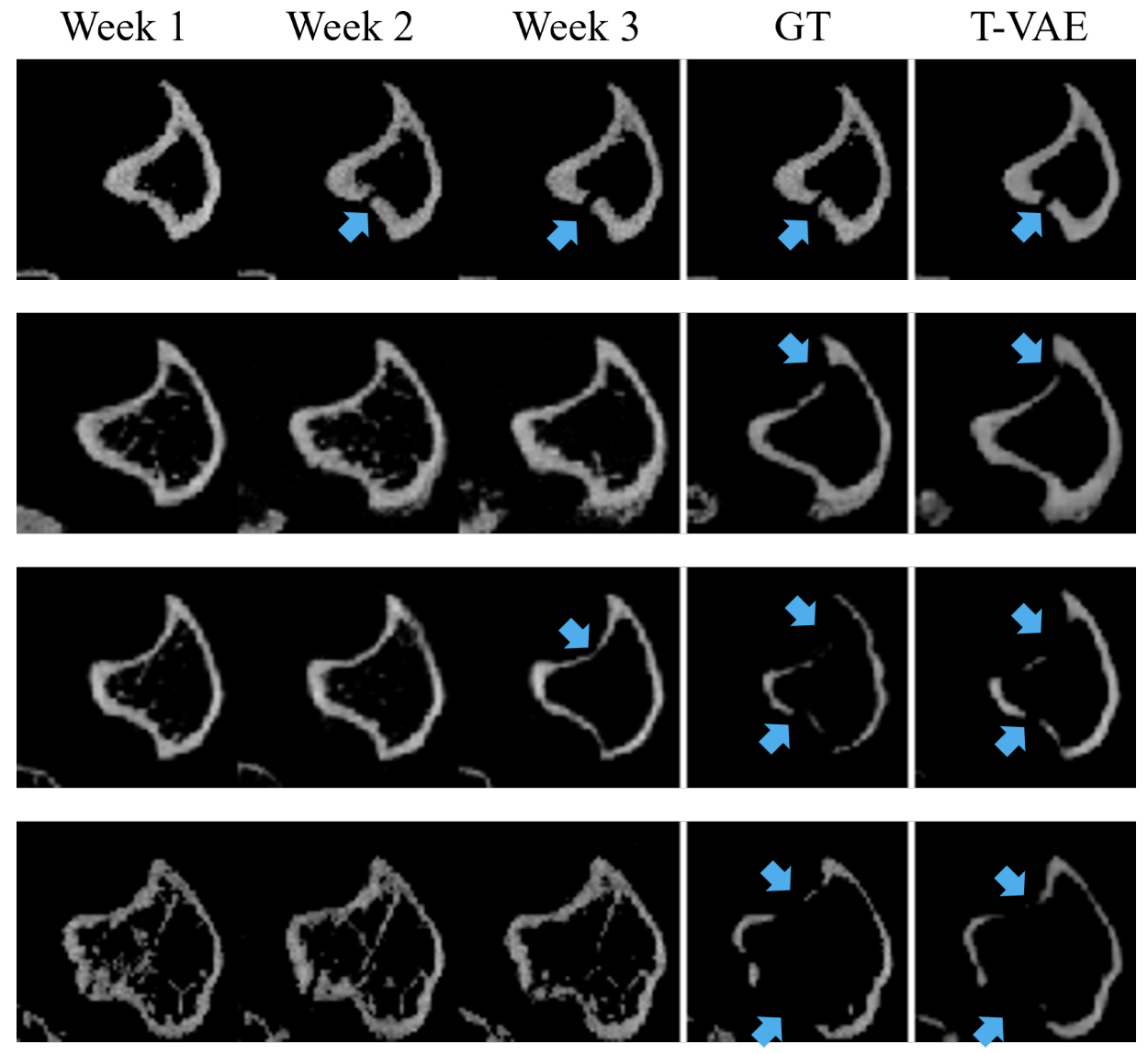
We adopt a temporal variational auto-encoder (T-VAE) model for bone osteolysis prediction
on computed tomography (CT) images of murine breast cancer bone metastases.
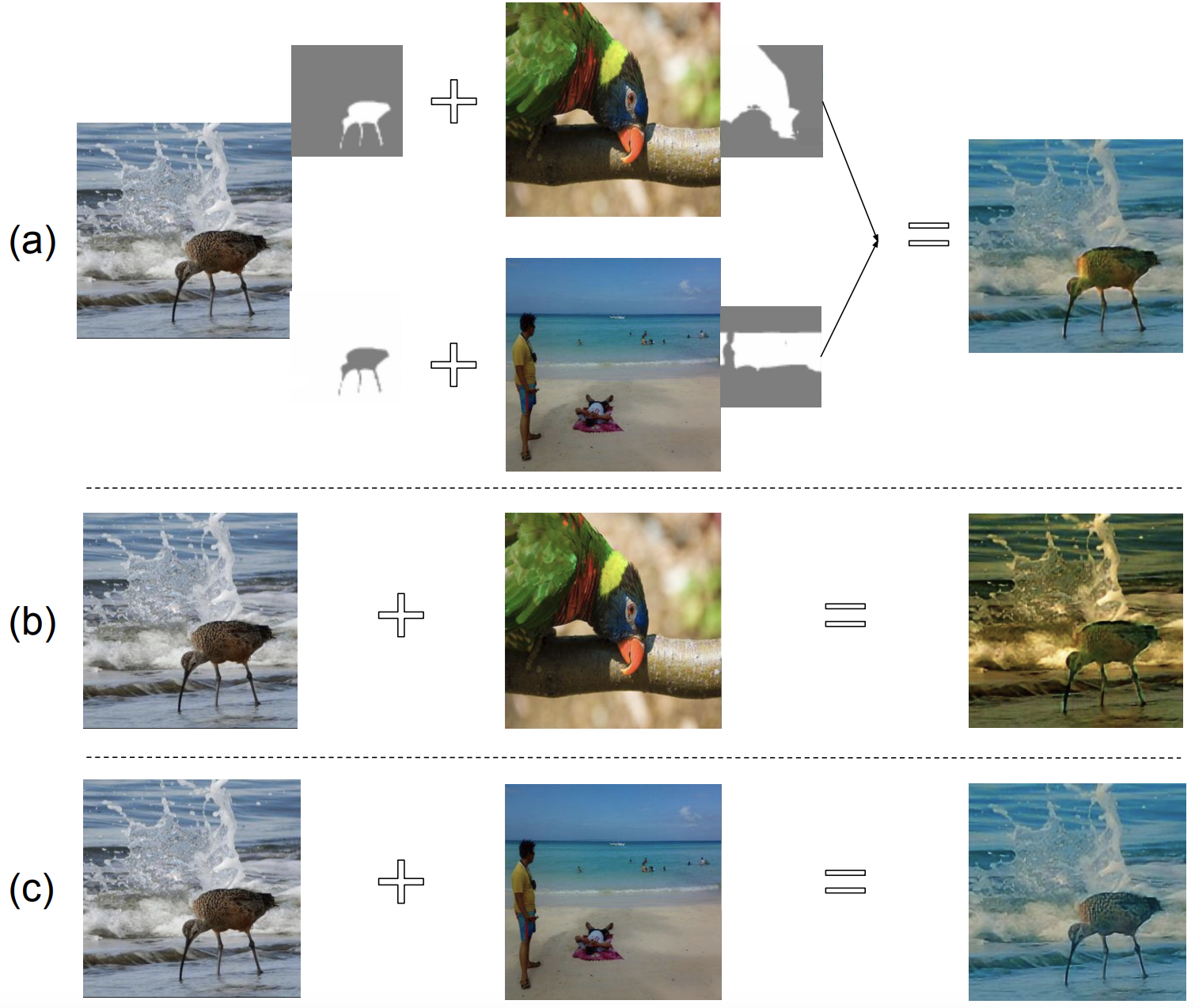
We introduce an important but still unexplored research task Image Sentiment Transfer and propose an effective
and flexible framework that performs image sentiment transfer at both the image level and the object level.
We tackle a challenging exemplar-guided image synthesis task, where the exemplar providing the style guidance is an arbitrary scene
image which is semantically different from the given pixel-wise label map.
We aim at transforming an image with a fine-grained
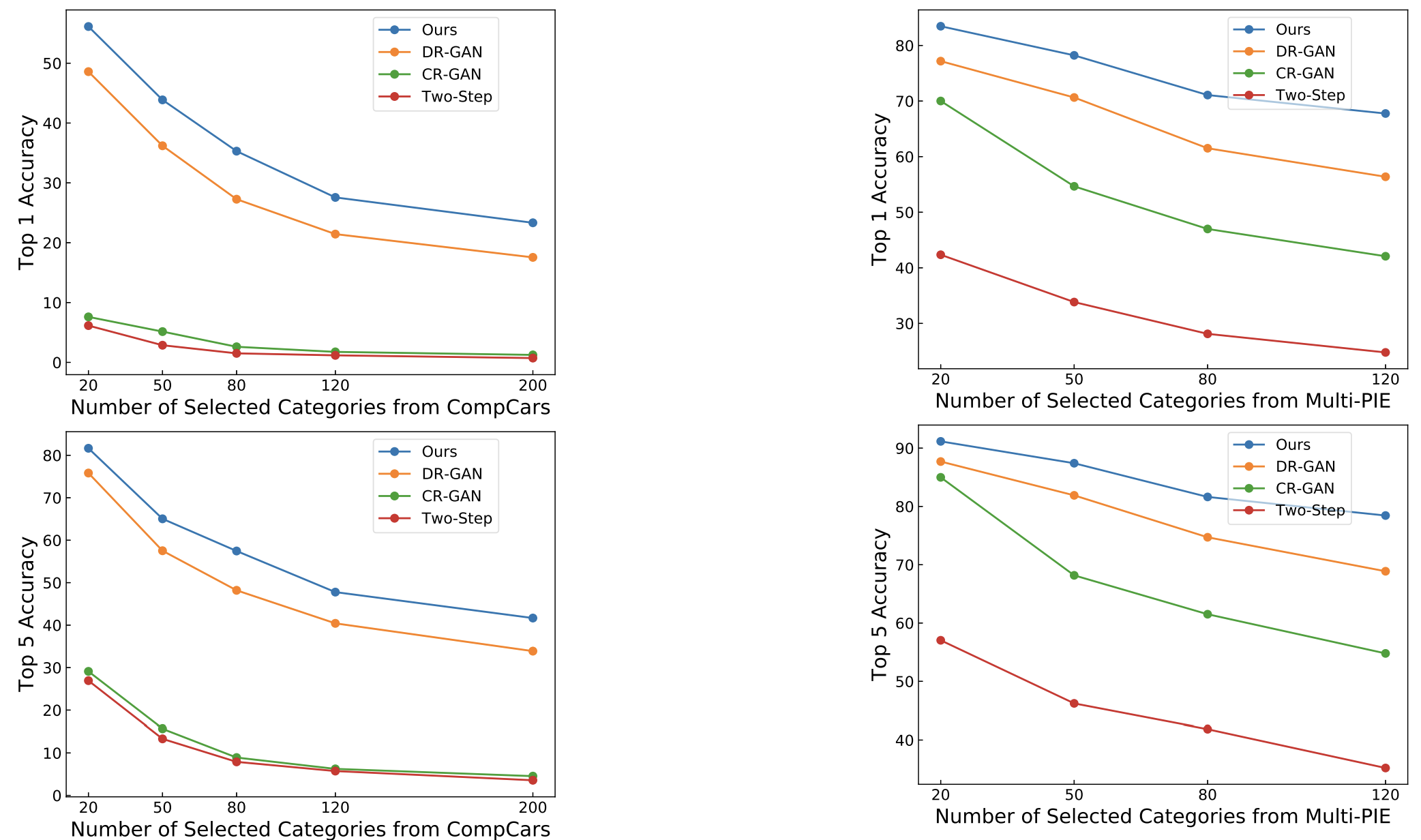
category to synthesize new images that preserve the identity of the input image, which can thereby benefit the subsequent fine-grained image recognition and few-shot learning tasks.
We frame the caricature generation task as a weakly
paired image-to-image translation task, and propose CariGAN model to generate high-fidelity caricature images from human faces with proper exaggerations.
We propose a foreground-aware image inpainting system that explicitly disentangles structure inference and content completion. Our model first learns to predict
the foreground contour, and then inpaints the missing region using the predicted contour as guidance.
We propose a two-stage GAN model to generate vivid yet content-preserving time-lapse videos from only a single starting frame. To this end, we desentangle the task into content generation and motion enhancement.
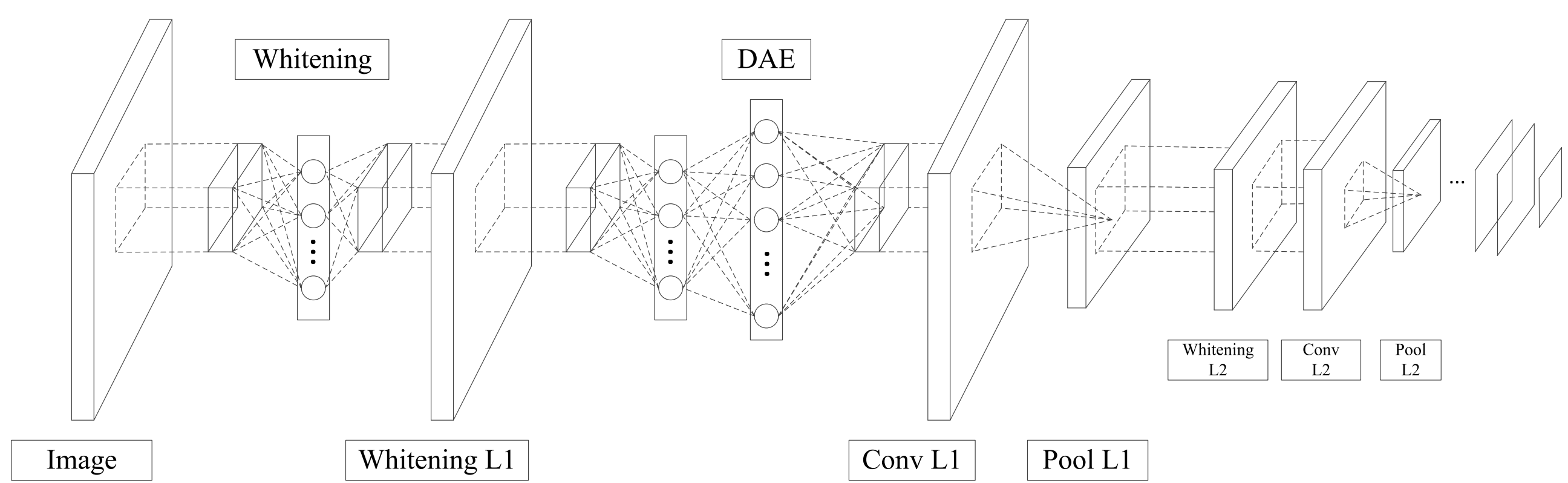
We proposes an unsupervised feature learning model, named the Stacked Convolutional Denoising Auto-Encoders,
that can map an image to hierarchical representations without
any label information.
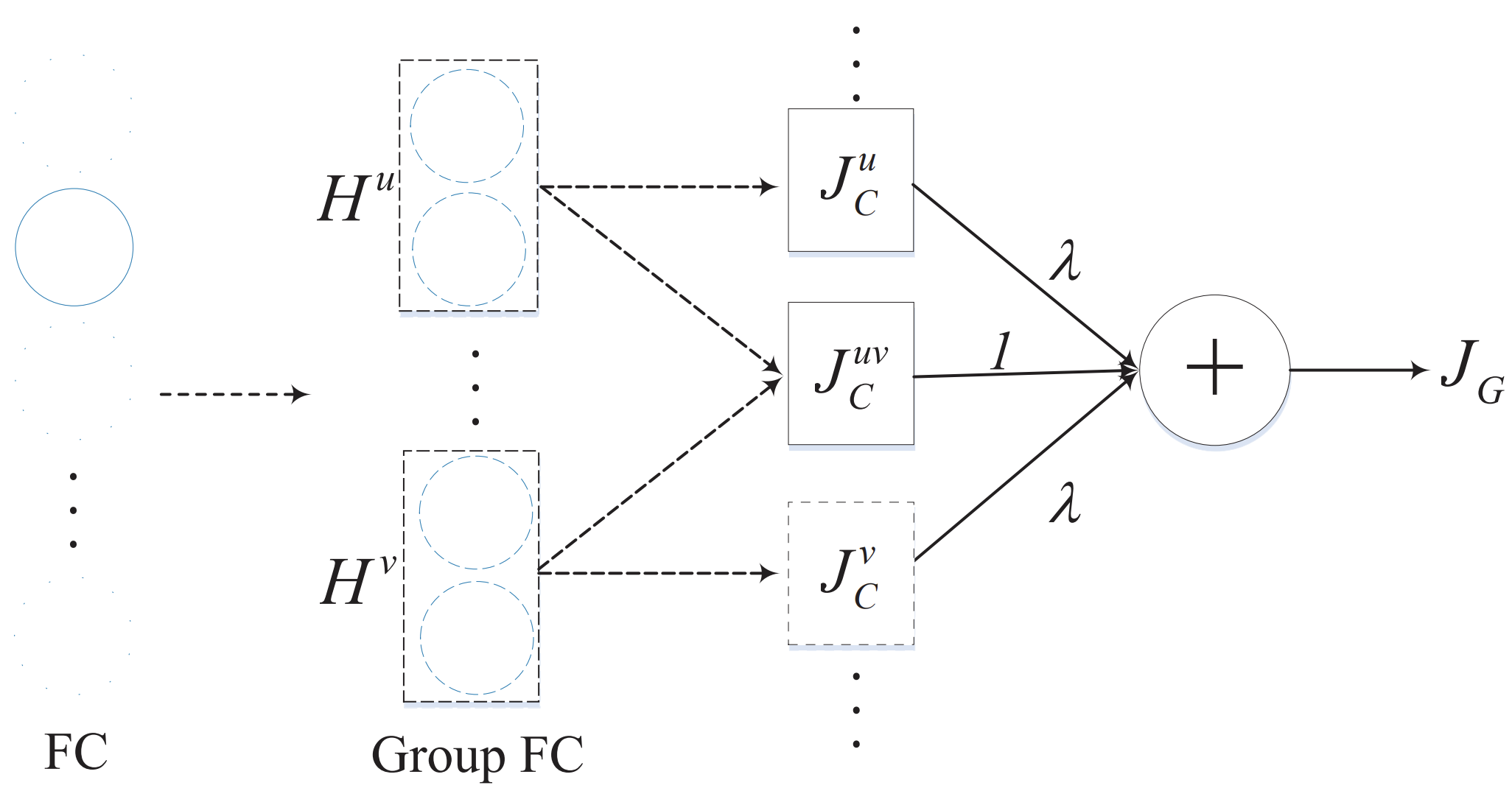
We propose a group regularization method, Structured Decorrelation Constraint (SDC), that regularizes the activations of the hidden layers in groups to achieve better generalization.
Mentoring
I am fortunate to have mentored and collaborated with a few talented researchers: